
Optymalizacja kosztów transkrypcji audio dla artykułów SEO – case study
Transkrypcje audio artykułów to skuteczne narzędzie do zwiększenia zaangażowania użytkowników i poprawy wskaźników behawioralnych istotnych dla SEO. Treści dostępne w wielu formatach (tekst + audio + ewentualnie wideo) trafiają do szerszego grona odbiorców i dłużej utrzymują ich na stronie — co dla Google jest sygnałem jakości. Audio pozwala dotrzeć do użytkowników, którzy preferują słuchanie treści (np. podczas jazdy samochodem, ćwiczeń) lub nie mogą czytać z powodów zdrowotnych czy sytuacyjnych. Plus dodatkowy kanał dystrybucji: wygenerowane audio można publikować jako podcast na Spotify, Apple Podcasts i YouTube — bez dodatkowej pracy nad treścią.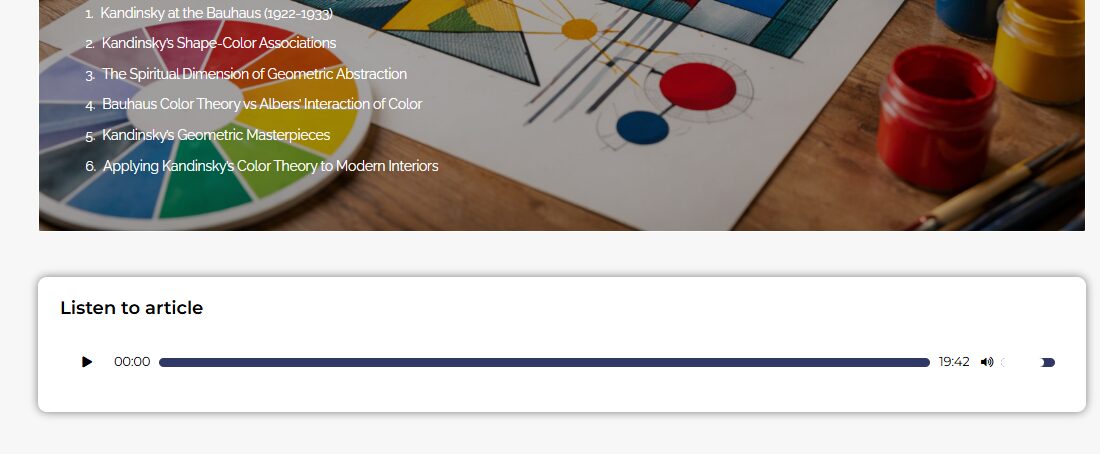
Player audio zintegrowany z artykułem – przykład implementacji na jednym z naszych projektów
Wyzwanie biznesowe
Dla jednego z naszych klientów z branży interior design potrzebowaliśmy wygenerować wersje audio ponad 20 artykułów eksperckich (średnio 1500-2000 słów). Wykorzystanie ElevenLabs wiązało się z wysokimi kosztami – jeden artykuł zużywał połowę miesięcznych kredytów na planie Starter ($11/mc). Dodatkowo długie teksty wymagały ręcznego dzielenia i łączenia w Audacity z powodu limitu długości. Koszt całego projektu wyniósłby $50-70, przy kilku godzinach manualnej pracy operatora.
Analiza dostępnych rozwiązań TTS
Przeanalizowaliśmy kluczowe platformy Text-to-Speech dostępne na rynku pod kątem trzech kryteriów: jakości syntezy mowy, struktury kosztów oraz możliwości automatyzacji przy dużych wolumenach treści.Odrzucone rozwiązania
TTSMaker (darmowe): Limit 1000 znaków na request eliminuje możliwość przetwarzania długich artykułów.
Wybrane rozwiązanie
- Głosy Neural2 z naturalną intonacją
- Brak sztywnych limitów długości
- Model pay-as-you-go ($4/1M znaków)
- $300 darmowych kredytów na start
- Pełna kontrola przez API – możliwość automatyzacji
Architektura rozwiązania
Stworzyliśmy system automatycznej generacji audio składający się z trzech warstw: autoryzacji, przetwarzania tekstu i produkcji plików wyjściowych. 1. Konfiguracja Google Cloud Platform Pierwszy etap to przygotowanie środowiska w Google Cloud Console i wygenerowanie kluczy dostępu do API: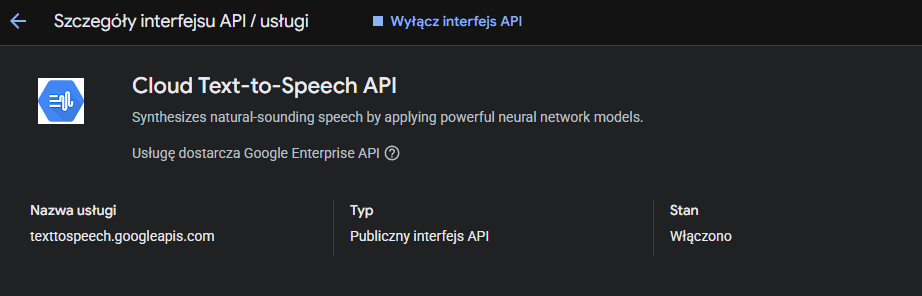
Cloud Text-to-Speech API w statusie "Włączono" – konfiguracja projektu w Google Cloud Console
- Rejestracja w Google Cloud Console (wymaga podpięcia karty, ale start z $300 kredytów)
- Utworzenie projektu dedykowanego pod TTS
- Włączenie Cloud Text-to-Speech API w bibliotece usług
- Stworzenie Service Account z rolą Cloud Text-to-Speech Administrator
- Wygenerowanie i pobranie klucza JSON do autoryzacji zapytań
Pro tip: Service Account pozwala na bezpieczną autoryzację bez eksponowania danych logowania. Klucz JSON działa jak certyfikat dostępu – można go używać w skryptach automatyzacyjnych bez interakcji z użytkownikiem.
/v1/text:synthesize w Google Cloud TTS ma ograniczenie do 5000 bajtów tekstu wejściowego na jedno zapytanie. Artykuły o długości 1500-2000 słów (~10,000-13,000 znaków) przekraczają ten limit wielokrotnie.
Dostępne są dwa podejścia:
/v1beta1/synthesizeLongAudio)
Przeznaczone dla bardzo długich tekstów, ale zapisuje wynik w Google Cloud Storage, co wymaga dodatkowej konfiguracji bucket'ów i pobierania plików.
Opcja B: Chunking tekstów (wybrana)
Podzielenie artykułów na fragmenty ~4500 znaków, wygenerowanie audio dla każdego fragmentu osobno, a następnie złączenie w jeden plik MP3. Prostsze w implementacji, daje pełną kontrolę nad plikami wyjściowymi.
google-cloud-texttospeech:
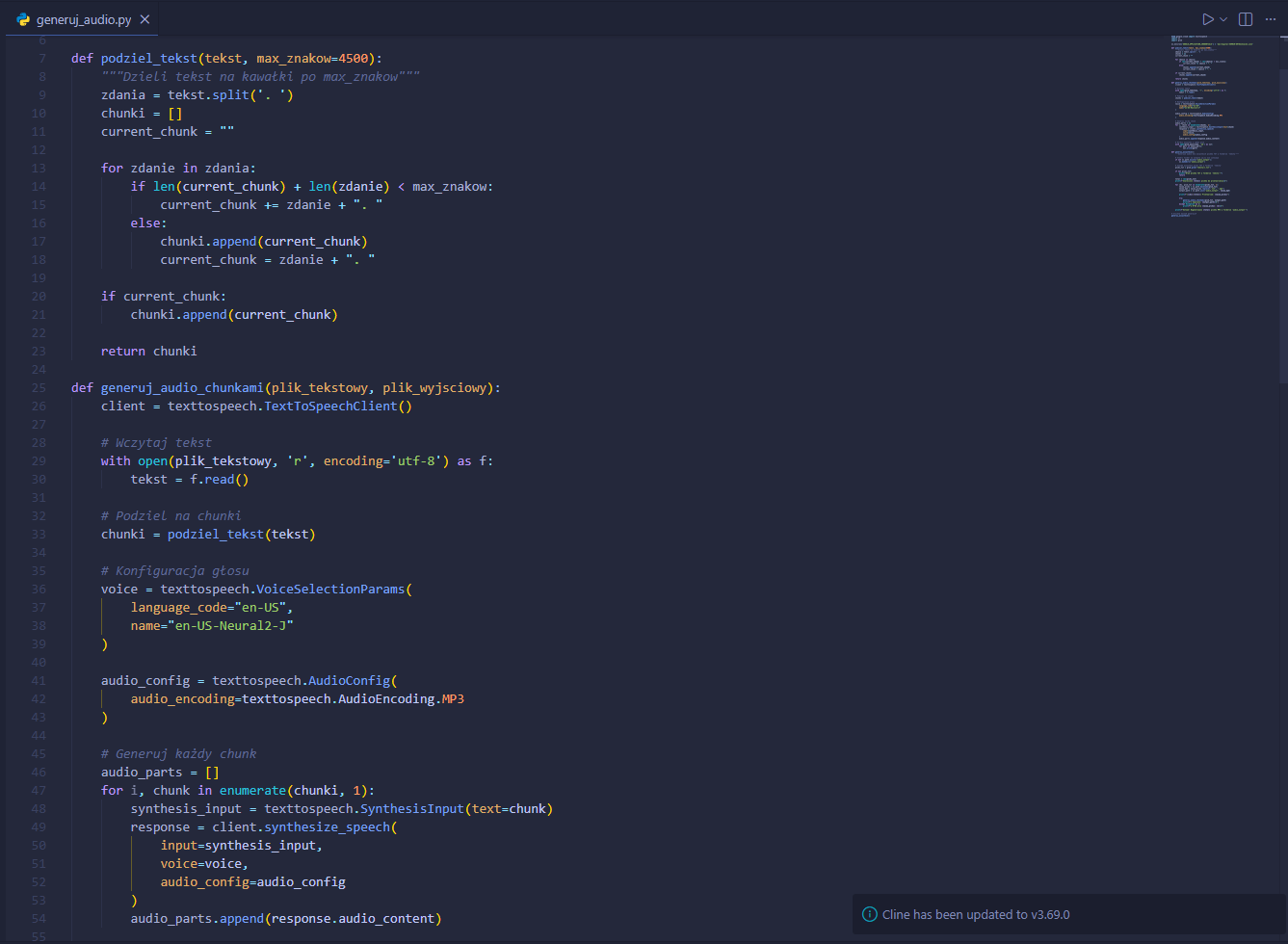
Fragment kodu Python – funkcja dzielenia tekstu na chunki i konfiguracja głosu Neural2
Kluczowe decyzje techniczne: Dzielimy tekst na granicach zdań (nie w połowie słowa), co zapewnia naturalność. Bufor 500 znaków poniżej limitu eliminuje ryzyko przekroczenia przy długich zdaniach złożonych.
Wybór głosu: Neural2 vs Wavenet
Google oferuje dwie główne rodziny głosów syntetycznych. Dla projektu wybraliśmy głosy z serii Neural2: Dla tekstów angielskich zastosowaliśmy głosen-US-Neural2-J (męski, amerykański akcent), który najlepiej oddawał profesjonalny, ekspercki charakter treści.
Automatyzacja: batch processing
Kluczową zaletą rozwiązania API jest możliwość przetwarzania wielu plików automatycznie. Stworzyliśmy prosty pipeline: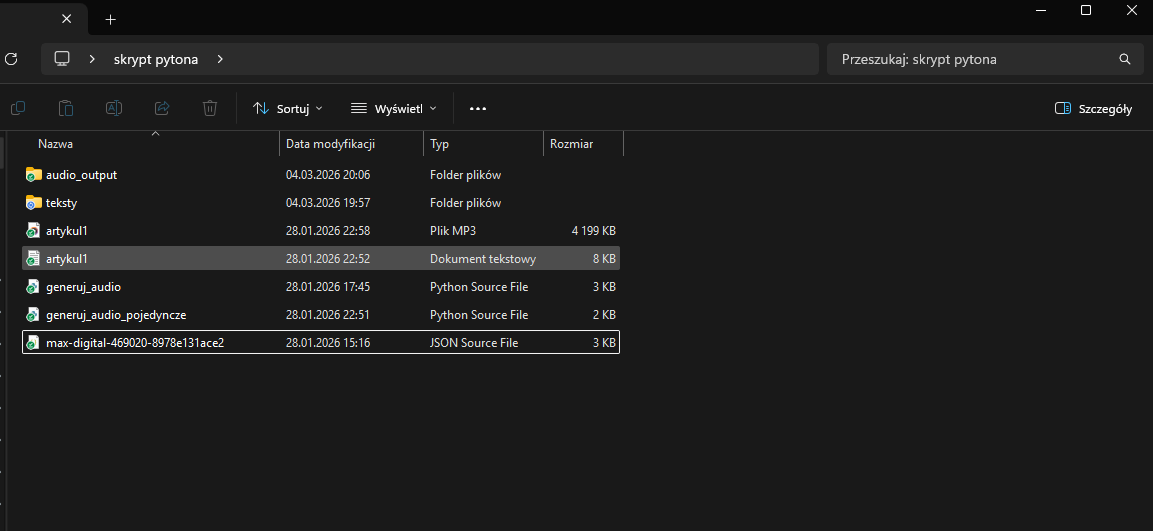
Struktura katalogów projektu – folder teksty/ z artykułami TXT, skrypty Python, klucz JSON i folder audio_output/ z wygenerowanymi MP3
Folder teksty/ – tu lądują pliki TXT z artykułami

Max Mazurkiewicz
FounderPOTRZEBUJESZ SPERSONALIZOWANEJ WYCENY?
Chcesz się na coś zdecydować ale od nadmiaru możliwości boli głowa? Skontaktuj się z nami, dobierzemy rozwiązanie do potrzeb Twojej firmy.
Umów się na konsultacjęSkrypt Python – iteruje przez wszystkie pliki, generuje audio
Folder audio_output/ – automatycznie utworzony, gotowe MP3
Output skryptu w PowerShell – automatyczne przetwarzanie 5 artykułów z progressem i potwierdzeniami zapisu
Jedno uruchomienie skryptu przetwarza wszystkie artykuły sekwencyjnie. Dla 20 artykułów (~30,000 słów łącznie) czas generacji wyniósł około 8-10 minut.Wyniki i wnioski biznesowe
Porównanie kosztów i czasu realizacji
ELEVENLABS (pierwotnie planowane)
$50-70
+ 3-4h pracy manualnej
GOOGLE CLOUD TTS (zrealizowane)
$0.48
+ 10 minut automatyzacji
Oszczędność: ~99% kosztów + eliminacja pracy manualnej
Kluczowe wnioski z projektu:
- Skalowalność rozwiązania – dodanie kolejnych 50, 100 czy 200 artykułów nie zwiększa kosztów jednostkowych ani czasu pracy
- Jakość głosów Neural2 – po testach A/B z grupą użytkowników serwisu nie zanotowaliśmy negatywnych opinii dotyczących syntetycznego charakteru audio
- ROI automatyzacji – czas poświęcony na setup (ok. 1h) zwrócił się już przy pierwszej paczce 20 artykułów
- Możliwość skalowania – system można łatwo rozbudować o integrację z WordPress API do automatycznego generowania audio przy publikacji nowych wpisów
Dla kogo to rozwiązanie?
Google Cloud TTS sprawdza się idealnie dla:- Agencji contentowych – produkcja audio dla dziesiątek klientów miesięcznie
- Wydawców treści – regularnie publikujących artykuły eksperckie, poradniki, case studies
- Serwisów e-learningowych – konwersja materiałów tekstowych na format audio
- Platform blogowych – zwiększenie zaangażowania i czasu spędzonego na stronie
Potencjalne rozszerzenia systemu
Po udanej implementacji podstawowego rozwiązania zidentyfikowaliśmy kilka kierunków rozwoju:Integracja z WordPress
Automatyczne generowanie i upload audio przy publikacji nowego posta. Możliwe przez WordPress REST API + Google Cloud Functions.
SSML customization
Wykorzystanie SSML (Speech Synthesis Markup Language) do precyzyjnej kontroli intonacji, przerw, akcentowania kluczowych fraz.
Multilang support
Automatyczne wykrywanie języka artykułu i dobór odpowiedniego głosu (PL, EN, DE, ES, FR). Google oferuje ponad 40 języków.
Analytics integracja
Tracking wskaźników engagement dla użytkowników korzystających z wersji audio (GTM events, GA4 custom dimensions).
Workflow publikacji w wielu formatach — dystrybucja audio
Wygenerowane audio nie kończy swojego życia jako MP3 na stronie. To dodatkowy aktyw treści, który można rozdystrybuować w wielu formatach bez dodatkowej pracy nad treścią:
- Embed audio na artykule — odtwarzacz HTML5 pod tytułem artykułu. Klient ma wybór: czytać lub słuchać. Dodaje wymiar dostępności (osoby z dysleksją, słabowidzące).
- Podcast na Spotify, Apple Podcasts, YouTube — odcinki podcastu generowane z artykułów blogowych. Spotify for Podcasters pozwala wgrać MP3 + tytuł + opis bezpośrednio. RSS feed automatycznie dystrybuuje do Apple Podcasts i Google Podcasts.
- YouTube z ścieżką audio + grafika — proste wideo, w którym tłem jest statyczna grafika (cover artykułu), a ścieżką dźwiękową wygenerowane audio. YouTube indeksuje to jako treść wideo i daje dodatkowe wejście SEO.
- Newsletter z opcją „posłuchaj" — email z linkiem do MP3 dla subskrybentów, którzy preferują słuchanie. Open rate w segmencie audio-friendly bywa wyraźnie wyższy niż w klasycznym tekście.
SEO audio — co realnie indeksuje Google
Google indeksuje audio przez transkrypt tekstowy (który już masz — to oryginalny artykuł), nie przez sam plik MP3. Praktyczne implikacje:
- Schema AudioObject + Article na podstronie z artykułem. To sygnał dla Google, że strona oferuje treść w dwóch formatach.
- Transcript w pełni dostępny na stronie — nie ukrywaj go za odtwarzaczem. Google musi mieć tekstową wersję, żeby rozumieć temat.
- Podcast RSS — submituj feed do Google Podcasts (przez Search Console — funkcja w Beta od 2024). Pozwala to wyświetlać podcasty bezpośrednio w SERP dla zapytań „podcast + temat".
- Indeksacja YouTube — wideo z audio + grafiką może rankować osobno w YouTube Search na podobne frazy. To dodatkowe wejście.
Koszt vs efekt — kiedy się opłaca
Generowanie audio przez Google Cloud TTS Neural2 to koszt rzędu kilkudziesięciu groszy za artykuł 5000 znaków. Przy publikacji 4-8 artykułów miesięcznie to budżet kilku złotych na całą sekcję audio. Komercyjne platformy SaaS do TTS pobierają porównywalne kwoty za pojedynczy artykuł — przy własnym pipeline koszty rozkładają się liniowo, bez progów cenowych za skalę.
Kiedy nie warto: dla blogów z 1-2 publikacjami miesięcznie i bez planu na dystrybucję podcastową. Sam embed audio na artykule daje marginalny wzrost zaangażowania, bez podcastu i kanałów alternatywnych ROI z konfiguracji pipeline'u jest słaby.
Kiedy warto: dla blogów z 10+ publikacjami miesięcznie, z planem na multi-channel distribution (web + Spotify + YouTube + newsletter). W tym scenariuszu audio staje się drugą warstwą zaangażowania bez dodatkowej pracy nad contentem.
